[DL-Adversarial Example] Understanding Adversarial Examples (1/4)
Introduction
NOTE. This post is a summary of a presentation entitled "Understanding Adversarial Examples" at "C&A Lab 2023-Summer Deep Learning Seminar". The corresponding slide is available at HERE.
For secure, trustworthy ML, potential threats against ML and their countermeasures should be investigated carefully. The adversarial attack is a type of attack to fool the target neural network by adding a subtle but intended perturbation to the target image. Several attack and defense (making a NN robust to such perturbations) methods were presented in various communities (i.e., computer vision, or security). Along with these studies, there have been several attempts to explain the reason for the existence of such adversarial examples.
More precisely, I will cover the following 4 papers:
- [EIS+19] Adversarial Robustness as a Prior for Learned Representations (arXiv'19)
- [SIE+20] Do Adversarially Robust ImageNet Models Transfer Better? (NIPS'20)
- [GJM+20] Short-cut Learning (Nature MI'20)
- [HZB+21] Natural Adversarial Examples (CVPR'21)
(In fact, I will present only the first one in this post. The remaining ones will be introduced in subsequent posts!)
Adversarial Robustness as a Prior for Learned Representations
In this study, they provide an extensive analysis of the learned representations (feature vectors) from adversarially robust NN models. They presented 4 observations from their experimental analyses, each of which is as follows:
(1) Robustly learned representations could be inverted well toward the original image.
(2) Robustly learned representations could be directly visualized well into their corresponding features.
(3) Interpolation between robustly learned representations could be interpolated well; the corresponding image seems to be continuously changed during interpolation.
(4) By combining (2) and (3), robustly learned representations could be utilized for feature manipulation, or image editing.
The overview of each observation is illustrated in the figure below.
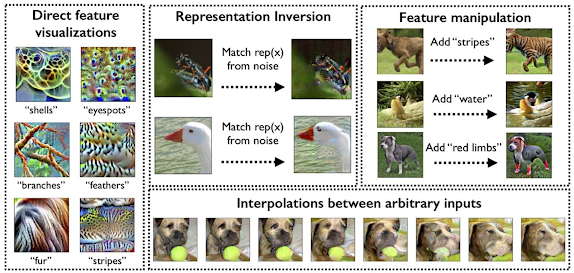
Representation Inversion
To examine whether the feature vector truly contains meaningful characteristics of the corresponding image, it is natural to find the pre-image of such a feature vector. For example, in the case of reconstruction attacks against face recognition systems, it is widely known that the quality of the inverted image is proportional to the performance (i.e., accuracy) of the target recognition system.
Despite some logical gaps, robust features would catch up with more "semantically" meaningful characteristics, and adversarially robust models are trained to learn such features. They demonstrate that the robust models behave as expected from this point of view.
In their experiment, they considered a simple inversion method by solving
$$x_{1}' = x_{1} + \arg\min_{\delta}||R(x_{1} +\delta) - R(x_{2})||_{2},\qquad(1)$$
where $x_{1}$ is a source image, $x_{2}$ is a target image, and $R$ is a feature extractor. This optimization problem can be easily solved by the gradient descent method. The inversion results for (non) robust models are given in the figure below.

As we can figure out, the inverted image from the standard classifier looks like an adversarial example, whereas that from the robust classifier resembles the target image. Remark that this can be shown as a natural consequence of the robust classifier in terms of its resistance against adversarial perturbation.
Interpolations
Moreover, robustly learned features can be interpolated well, just like latent vectors in generative modeling, e.g., GANs or VAE. This result also supports the fact that robustly learned features behave better than ordinary feature vectors. The result of interpolation is given in the below Figure. Compared to the naive interpolation with respect to pixel values, the interpolated image from the robustly learned features seems to be changing in a continuous way.

Then, how about non-robust ones? They also provided the result for addressing this, but I personally think that this example looks quite controversial; In my opinion, these images also change continuously during the interpolation. Despite this, still the images in the above figures look more natural than those depicted below.

Direct Visualization of Features
According to the aforementioned two results, one may be convinced that the robustly learned representations truly contain something "semantic" or "important". Then, a natural question follows: can we visualize a certain feature vector, e.g., (1,0,...0), obtaining a seemingly meaningful image? By using the inversion tool introduced in 2.1, the authors address this question. More precisely, they slightly modify the optimization problem (1) in the direction that maximizes a component of the chosen coordinate, as follows:
$$x_{1}' = x_{1} + \arg\max_{\delta} (R(x_{1} + \delta))_{i}.$$
Here, $(R(x))_{i}$ stands for the $i$-th coordinate of $R(x)$.
On the choice of source image $x_{1}$, they use two images, including an image of a dog and a random noise. They also test a non-robust model for comparison. The results are illustrated in the figure below:

This figure indicates that we can successfully visualize each feature in the adversarially robust model, whereas its counterpart did not! Remark that some previous works studied the visualization of features via specific regularization techniques, but these results were still insufficient to produce a meaningful image when viewed by humans.
Feature Manipulation
In the literature of generative modeling, feature manipulation (or image editing) is one of the famous applications using the properties of latent vectors. Image editing can be done by utilizing the interpolation of specific latent vectors (e.g., latent vectors corresponding to blonde hair, or a smiling expression, ...). As we observed in 2.2 and 2.3, it seems that such manipulations are also possible for robustly learned features. In the following figure, they provide some examples for this: adding stripes or red limbs to the images of dogs.

Summary & Comment
In this paper, they provide an extensive analysis of the learned representation from robust models. In the perspective of secure ML, adversarially robust models are necessary in order to defend against adversarial examples, but according to this paper, it is expected that the adversarially robustness would make reconstruction attacks easier. Thus, more systemic studies involving security would be necessary.
0 comments:
댓글 쓰기