Introduction
NOTE. This post is a summary of a presentation entitled "Understanding Adversarial Examples" at "C&A Lab 2023-Summer Deep Learning Seminar". The corresponding slide is available at HERE.
ALSO NOTE. This is the second post for "Understanding Adversarial Examples." If you did not read my first post, then it would be beneficial to read that for the sake of better understanding!
When training a neural network with deep learning, the amount of available data plays an important role in the performance of the resultant network. Of course, for some tasks, such as image classification on web-crawled data or recognizing the facial images of celebrities, collecting sufficient, large data for training is not that difficult. However, on the other hand, there are still many tasks where collecting a large-scale dataset is almost impossible, such as medical data or biometrics data that requires special equipment for collecting the data, e.g., finger veins.
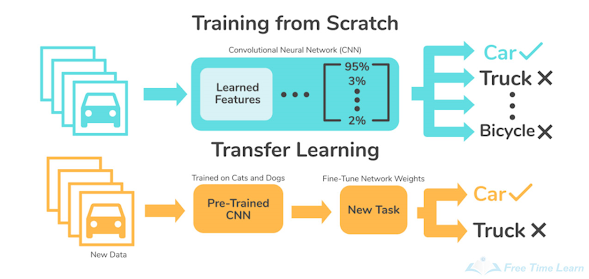
To address this problem, several solutions would be considered. For example, some studies elaborated on creating a synthetic dataset for exploiting recent sophisticated generative modeling techniques. But one traditional and simple approach is transfer learning. Transfer learning is an important branch of deep learning literature. By fine-tuning the pre-trained network for a task where a large number of data can be easily collected, i.e., image classification via the ImageNet dataset, the tuned network could obtain better accuracy with a smaller amount of data. The following simple figure briefly illustrates how transfer learning works:
At that moment, an important question follows: What should we do to improve transfer learning, and what is the main reason for its success? In this post, I will present the second paper that identifies the relationship between transfer learning and the adversarially robust model.
- [EIS+19] Adversarial Robustness as a Prior for Learned Representations (arXiv'19)
- [SIE+20] Do Adversarially Robust ImageNet Models Transfer Better? (NIPS'20)
- [GJM+20] Short-cut Learning (Nature MI'20)
- [HZB+21] Natural Adversarial Examples (CVPR'21)
Do Adversarially Robust ImageNet Models Transfer Better?
Conventional wisdom says that the main factor of enhancing the accuracy of transfer learning in the downstream task is the accuracy of the pre-trained model in the upstream task: A better pre-trained model would transfer its knowledge better. It would be correct if these two tasks were not that different, more precisely, if the distribution of each dataset was quite similar. However, this is not the case in many applications of transfer learning.
Then, for the sake of better transfer, what are the desirable properties that the pre-trained model would have? In terms of representation learning, it would be reasonable to consider whether the pre-trained model learned reasonable, robust representations from an upstream task.
As we saw in my first post, it is experimentally verified that the adversarially robust classification model has several advantages in terms of learned representation, including better representation inversion, direct visualization of representations, or feature interpolation. From this point of view, it seems natural to infer that robustness plays a significant role in the success of transfer learning.
This paper is the first study to elaborate on the aforementioned perspective. They conducted extensive analyses of various downstream tasks to demonstrate the effectiveness of adversarially robust models in transfer learning. Moreover, they provided several analyses and discussions, including the relation between the extent of robustness and the "granularity" of the dataset, and the correlation of the accuracy between the pre-trained model on the upstream task and the fine-tuned model on the downstream task when the notion of robustness is engaged. The following table is a quick summary of the contribution of this paper:
Experimental Setting
Transfer learning can be classified into two types with respect to the frozen parameters during fine-tuning: Fixed transfer learning and full transfer learning. The former freezes all parameters of the pre-trained model except those of the last layer, whereas the latter trains all parameters during fine-tuning.
In the sense of the robustly trained pre-trained model, it seems more natural to consider the fixed transfer learning setting than its counterpart, because it cannot be ensured that the adversarial robustness is preserved during full transfer learning. In addition, from the perspective of the robust feature model proposed by their previous study [IST+19], fixed transfer learning itself could be understood as a fine-tuning of the classifier without modifying the previously learned robust features.
However, they considered these two settings simultaneously because there was evidence that there is a positive correlation between the accuracy of the fine-tuned model from fixed transfer learning and the full one.
Results on Image Classification
In order to support their claim, they considered several downstream tasks and pre-trained models with several architectures. Every pre-trained model is trained on the ImageNet dataset. They considered the following datasets and architectures:
- Datasets: Caltech-101/256, CIFAR-10/100 / FGVC-Aircraft / Birdsnap / Stanford Cars / DTD / Flowers / Food-101 / Oxford-IIIT Pets / SUN397
The following images are examples of each dataset (Left: Caltech-101 / Middle: FGVC-Aircraft and Stanford Cars / Right: DTD)
- Architectues: ResNet18 / ResNet50 / WideResNet50-2 / WideResNet50-4
The experimental results are given in the below figure (Upper: Fixed transfer learning, and Lower: Full transfer learning)
This figure indicates that their insight indeed coincides with the experimental result: In almost all tasks, the result from the robust pre-trained models consistently outperforms their non-robust, standard counterparts.
In addition, they tested object detection tasks, and the results are given as follows.

What Makes Transfer Learning Successful? An Answer.
As I mentioned earlier in this post, conventional wisdom on the accuracy of transfer learning has only a 1-dimensional relationship with that of the pre-trained model in the upstream task. However, this paper suggests that such a relation was in fact 2-dimensional; both the accuracy and robustness of the pre-trained model are taken into account. Although the presented results are sufficient to demonstrate this, they provided another analysis to clarify the relationship between them. For this, they first described the relation between ImageNet (upstream task) accuracy and several accuracies from downstream tasks while varying the amount of robustness $\epsilon$. The corresponding figure is presented below, which indicates that the linear relation is often violated when robustness is taken into account.
In addition, they provide a more straightforward analysis by evaluating correlation coefficients. The following table indicates that (1) there is a positive correlation between the accuracies of upstream and downstream tasks, and (2) such a relation becomes stronger for adversarially robust models.
How Much "Robust" Should Be?
On the above figure, one may figure out that the optimal amount of robustness ($\epsilon$) for the pre-trained model differs for each dataset. To understand this situation, they hypothesized that the "granularity" of the dataset plays an important role in the desirable $\epsilon$: As the classifier is required to distinguish finer features, the most effective value of $\epsilon$ becomes smaller. Although it would be a rather abstract notion, one simple measurement to evaluate the granularity is the resolution of each dataset. For example, CIFAR-10/100 is comprised of images of 32X32 resolution, whereas the Caltech-101 dataset consists of images with much finer resolution, say 200X200. They experimentally checked the effect of resolution by fixing all resolutions of each dataset with appropriate interpolations. The following result is the accuracy of each downstream task when the resolution is fixed to 32X32.
This figure indicates that their claim for granularity as a resolution coincides with their intuition. As an interesting future work, I think that the notion of granularity should be clarified; only considering the pixel difference between images seems insufficient to fully compare the granularity of datasets. Of course, it would be a challenging task to define a reasonable measure for granularity, I hope that their analysis of granularity in terms of adversarial perturbation can be a useful milestone to enhance our understanding of image classification.
Summary & Comment
Their study is the first to identify somewhat non-intuitive results from conventional wisdom: Conventional wisdom says that the accuracy of transfer learning in the downstream task is proportional to the pre-trained model. Adversarially robust training does harm accuracy. Nevertheless, it shows a better performance on transfer learning. They provide extensive analyses to support their claim, showing that their observation is not restricted to the choice of the downstream task or the architecture of the pre-trained model.
In my opinion, the following three future works might be interesting to understand the learning itself. (In fact, I already mentioned one of them.)
(1) Applicability to Knowledge Distillation
Knowledge distillation is a method to "distill" the knowledge of apre-trained model (called the "teacher" model) to train a relatively small model (called the "student" model) in an efficient way. Knowledge distillation is also an important branch of deep learning, because it enables us to utilize high-performance neural networks in an environment with limited computational resources, such as applications on mobile devices. In terms of utilizing the knowledge from the upstream task, it seems to have a strong relationship with transfer learning. Thus, it is natural to consider the applicability of this result to knowledge distillation. However, we should keep in mind that unlike transfer learning, the capacity of the student model is considerably smaller than that of the teacher model. From the perspective of robust learning and its "semantically" meaningful learned representation, the smaller model capacity would plunder the chance to learn such representations.
(2) Applicability to Face Recognition Tasks.
In my opinion, face recognition is clearly a finer-grained task than general image classification, such as ImageNet or CIFAR, because the number of shared characteristics of faces is much larger than that of web-crawled images. For example, almost all humans have two eyes, two ears, one nose, one mouth, and an oval-shaped head. Moreover, considering the social impact in terms of ML security, along with the fact that face recognition systems have already been deployed in several practical (and commercial) applications, studying the robustness of face recognition models is also a meaningful topic.
(3) The notion of granularity: I already explained. PASS!







0 comments:
댓글 쓰기